인덱스 순차 파일 구조의 가장 큰 단점은 파일이 커질수록 인덱스를 찾아내는 성능과 데이터를 연속적으로 스캔하는 성능이 감소한다는 점이다. 이러한 성능 감소는 파일을 재구성하면 제거할 수 있지만 빈번한 재구성은 바람직하지 않다.
데이터의 삽입과 삭제가 이뤄져도 성능을 유지하는 몇몇 인덱스 구조 중에서 B+ Tree 인덱스(B+ Tree index) 구조를 가장 널리 사용하고 있다. B+ Tree 인덱스(B+ Tree index)는 트리의 루트 ⇒ 단말노드(리프노드) 모든 경로의 길이가 동일한 균형 트리(balanced tree)이다. 루트 노드를 제외한 비 단말 노드는 [n/2] ~ n개의 자식을 갖고 있고 이때 n은 특정한 트리에 대해 고정된 값이다.루트는 2 ~ n개의 자식을 갖고 있다.
B+ Tree 구조는 삽입 & 삭제 시 성능 overhead(부담)와 공간 overhead(부담)를 부과하지만성능 overhead의 경우 파일의 변경이 많은경우에 파일 재구성 비용을 피할 수 있어서 어느 정도 수용할 수 있다.공간 overhead의 경우 부여한 공간의 절반 이상만 사용하고 있어서 낭비하는 공간이 있게 되는데 이 역시 B+ 트리 구조의 성능 이익을 고려할 때 수용할 수 있다.
1. B+ 트리의 구조
B+ 트리 인덱스는 다계층 인덱스이지만 다계층 인덱스 순차 파일과는 구조가 다르다. 지금은 중복 key값이 없다고 가정하자.
즉, 각각의 검색 key는 고유하다고 가정하고 비고유 검색 키는 나중에 다룬다.
아래 그림은 B+ 트리의 대표적인 노드를 보여준다.
하나의 노드가 n-1개의 검색 key값 K1, K2, ..., K(n-1)과 n개의 포인터 P1, P2, ..., Pn을 포함한다.
노드 안의 검색 key 값은 정렬된 순서로 유지된다. 때문에 i < j ⇒ Ki < Kj가 성립한다.

- 단말 노드(leaf node)의 구조
i = 1, 2, ..., n-1일 때포인터 Pi는검색 key 값 Ki을 가지는 파일 레코드를 가리킨다.
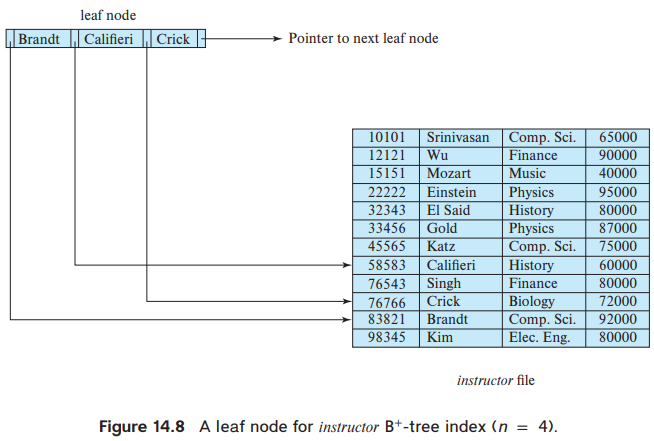
아래 그림은 instructor 파일의 B+ 트리에서의 단말 노드를 보여준다. (n = 4 & 검색 key값 = name)
(P1은 K1 = Brandt를 가진 레코드를 가리킴 / P2는 K2=Califieri를 가진 레코드를 가리킴)
- 특정 노드에 검색 key값을 할당하는 방법
각 단말 노드는 n-1개 까지의 값을 가질 수 있는데 단말 노드는 적어도 [(n-1)/2]개의 값을 포함해야 한다.
위 예제에서는 n = 4이므로 각 단말노드는 적어도 2개, 많으면 3개의 값을 가진다.
Li와 Lj가 각각 단말노드이고 i < j 이면 Li에 있는 모든 검색 key값 < Lj에 있는 모든 검색 key값이 성립한다.
만약 B+ 트리 인덱스가 밀집 인덱스로 사용된다면 단말 노드에 모든 검색 key값이 나타나야 한다.
- 포인터 Pn의 사용
각각의 단말노드는 검색 key값을 기반으로 순서대로 저장되어 있다. 그래서 단말 노드를 검색 key 순서로 서로 연결하기 위해서 Pn을 사용한다. 이러한 순서는 파일의 연속적인 처리를 능률적으로 할 수 있게 해준다.
- 비단말 노드(non-leaf node) 또는 내부 노드 (internal node) ⇒ 단말 노드 상에서 다계층 (희소 - sparse) 인덱스를 형성한다.
비단말 노드의 구조는 모든 포인터가 트리의 노드에 대한 포인터 인 것만 빼면 단말 노드의 구조와 동일하다.[n/2] ~ n개의 포인터를 가질 수 있다. 하나의 노드가 갖는 포인터의 개수를 팬아웃(fanout)이라 한다.
ex) m(m≤n)개의 포인터를 갖는 노드가 있다.
i = 2, 3, ..., m-1 일 때, 포인터 Pi는 Ki-1 ≤ (검색 key값) < Ki 을 만족하는 검색 key값을 포함한 서브트리를 가리킨다.
루트 노드는 하나의 노드로 구성된 트리가 아닌 이상 적어도 2개의 포인터를 가져야 하고 [n/2]보다 더 적은 포인터를 가질 수 있다.
이러한 조건들을 만족한다면 B+ 트리를 항상 구성할 수 있다.
- instructor (n = 4) 에 대한 B+ 트리 (간략한 설명을 위해 null 포인터를 생략 & 화살표가 없는 포인터 필드는 null값으로 간주)

- n = 6인 instructor 파일의 B+ 트리
n = 4인 B+ 트리보다 높이가 작은 것을 알 수 있다.

B+ 트리는 모두 균형 트리이다. 즉, 루트 -> 단말 노트까지의 모든 경로의 길이가 동일하다. 이 특징을 만족해야 B+ 트리라고 할 수 있다. B+의 B는 balanced를 의미한다. 이렇게 맞춰놓은 균형이 있어서 검색, 삽입, 삭제의 성능이 좋다.
일반적인 검색 key는 중복된 값을 가질 수 있다. 고유하지 않은 검색 키를 처리할 수 있는 방법은 트리구조를 수정해서 각 검색 key가 해당 레코드를 가리키게 하는 것이다. 하지만, 이러한 방식은 이전 기법보다 훨씬 복잡하고 특정 key에 대한 record 포인터의 개수가 매우 많다면 비효율적인 접근을 초래할 수 있다.
그래서 대부분의 DB를 구현할 때 검색 key는 다음과 같이 고유하게 만든다.
- 릴레이션 r의 검색 key 속성 a_i가 고유하지 않다고 가정한다. / A_r은 r의 주요 키이다.
그러면, 인덱스를 구축할 때 고유한 복합 검색 키인 (a_i, A_p)를 사용한다. 이에 대한 문제는 이후에 5번째 파트에서 자세히 다룬다.
지금까지의 예제는 중복이 없다고 가정하고 일부 고유하지 않은 검색 key에 대한 인덱스를 사용했다.
그러나 실제로 대부분의 DB는 중복을 확실하게 제거하기 위해 내부적으로 추가 속성을 자동으로 추가한다.
2. B+ 트리에서의 질의(queries)
검색 key값 v를 가지는 모든 레코드를 찾는다고 하자.
- 위 작업을 수행하기 위한 find(v) 함수의 의사코드

이때, 검색 key값은 중복이 없고 특정 검색 key값을 가지는 레코드가 최대 1개만 존재한다고 하자.
직관적으로 보면 find 함수는 트리의 루트에서부터 트리 내부에 존재하는 특정 값을 포함하는 단말 노드를 찾을 때 까지 아래방향으로 탐색한다 .
'DB System Concepts 7th' 카테고리의 다른 글
| [DB] 14-2. 순서 인덱스 (0) | 2023.08.21 |
|---|---|
| [DB] Chapter 14. 인덱싱 & 14-1. 기본 개념 (0) | 2023.08.18 |
| [DB] 13-7. 메인 메모리 DB의 저장구조 (0) | 2023.08.18 |
| [DB] 13-6. Column-Oriented Storage (0) | 2023.08.06 |
| [DB] 13-5. Database Buffer (0) | 2023.08.05 |