DB는 OS에 저장되어 있는 수많은 여러 파일들과 매핑되어 있다. 이 파일은 영구적으로 디스크에 저장된다.파일은 논리적으로 레코드의 연속으로 구성되어 있다. 각각의 레코드들은 디스크 블록과 매핑되어 있다.파일은 OS에서 기본적인 구성으로써 제공되기 때문에 파일 시스템이 있다고 추정할 수 있다.
여기서 우리는 파일을 논리적인 데이터 모델로 표현하기 위한 방법으로 생각할 필요가 있다.
각각의 파일은 논리적으로 블록이라는 단위로 나뉜다. 블록이란 저장장치의 분할과 데이터 전송의 단위이다.
대부분은 블록 사이즈를 4~8KB 정도로 지정하고 상황에 따라 여러 크기를 가질 수 있다.
블록은 여러 개의 레코드들을 포함할 수 있다. 그래서 모든 레코드는 블록보다 작다라는 추정을 할 수 있다.
(물론, 이미지와 같은 큰 데이터 요소들은 블록보다 큰 경우도 있다. 13.2.2에서 어떻게 큰 데이터를 다루는지에 대해 간단하게 살펴볼 것이다.)
그리고, 각각의 레코드 전체는 하나의 블록에 포함되어 있다. 즉, 하나의 레코드의 일부만 하나의 블록에 저장될 수 없다.
이렇게 제한을 함으로써 데이터 접근을 간단하고 빠르게 할 수 있다.
관계형 데이터베이스에서 서로 다른 relation의 튜플들은 일반적으로 사이즈가 다르다.
그래서 DB와 파일을 매핑하는 방법으로 2가지가 있다.
1) Fixed-Length : 여러 개의 파일을 사용해서 레코드들을 고정된 길이로 저장하는 방법
2) Variable-Length : 다양한 길이로 구성된 레코드를 포함시킬 수 있도록 구성하는 방법
각각에 대해서 살펴보자.
1. Fixed-Length Records
ex) 대학교의 데이터베이스에서 instructor라는 레코드들로 이뤄진 파일이 있다고 하자.
파일의 각각의 레코드들은 아래와 같이 이뤄졌다. 각각의 character는 1byte / 숫자 salaray는 8bytes로 이뤄졌다고 하자.
type instructor = record
ID varchar(5);
name varchar(20);
dept_name varchar(20);
salary numeric(8, 2);
end위와 같은 구성에서 각각의 레코드가 가질 수 있는 용량은 53bytes이다. 아래와 같이 레코드의 최대 용량을 저장하는 방식으로 데이터를 저장했다고 하자.
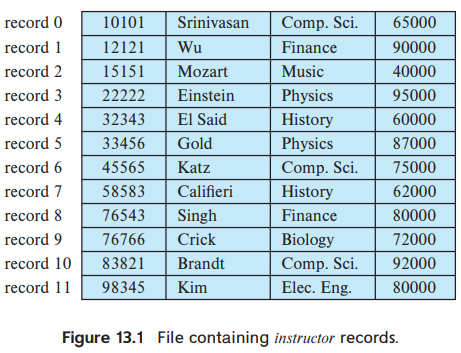
이렇게 되면 2가지 문제점이 발생한다.
- 만약에 블록 크기가 53의 배수가 아닌 이상 블록의 경계를 넘는 일이 발생한다. 즉, 레코드의 크기가 53을 넘어버려서 각 레코드가 다른 블록에 저장될 수도 있다는 뜻이다. ==> 이렇게 되면 하나의 레코드를 읽거나 쓰는데 2개의 블록에 접근해야 하는 상황이 벌어진다.
- 레코드를 삭제하는 것이 어렵다. 삭제된 레코드에 의해서 차지된 공간은 파일의 다른 레코드에 의해서 채워져야 한다. 그렇지 않으면 삭제된 부분을 무시할 수 있도록 삭제된 레코드의 부분을 표시해줘야 한다.
각각의 문제점을 해결하기 위해서 아래와 같은 해결책이 제시된다.
- 최대한 블록의 크기에 맞는 레코드들을 할당한다. (레코드의 크기를 블록 사이즈로 나눠서 나머지는 버리는 방식으로) 하지만, 이렇게 되면 각 블록의 남은 부분은 사용하지 못하고 남겨야 한다.
- 레코드를 삭제할 때 삭제된 부분을 채워주기 위해 기존 데이터 들을 한 칸 씩 앞으로 땡겨주는 방식을 채택할 수 있다. 하지만, 옮겨야 하는 레코드의 개수가 많다면 많은 비용을 소모하게 된다. 그래서 맨 마지막 에 있는 레코드를 삭제된 부분에 넣는 방법을 생각할 수 있다. 하지만, 이 방법은 좋지 않다. 추가적인
block access를 요구하기 때문이다.
삽입(insertion)은 삭제(deletion)보다 더 빈번하기 때문에 삭제된 레코드가 차지했던 부분을 그대로 두는 걸 받아들일 수 있고 해당 공간을 다시 쓰기 전에 추가적인 삽입을 기다린다.
앞서 삭제된 레코드의 부분을 표시한다고 했는데 이는 적절하지 못한 방법이다. 왜냐하면, 삽입을 할 때 이용가능한 공간을 찾기 어려워지기 때문이다. 그래서 다른 구조가 있는지 살펴봐야한다.
파일의 시작 부분에 파일 헤더라는 바이트의 특정 숫자를 할당한다. 헤더는 파일에 대한 다양한 정보를 담을 것이다.
- 삭제된 레코드의 주소를
free list와 함께 표시한 그림 (레코드 1, 4, 6이 삭제된 상황)
이때, 삭제된 레코드들을 LinkedList 형태로 저장한다.
이 상황에서 새로운 레코드를 삽입한다면 헤더가 가리키고 있는 레코드를 사용하면 된다. 더 이상 없다면 파일의 맨 마지막에 삽입하면 된다.
고정된 길이의 레코드로 이뤄진 파일의 삽입과 삭제는 구현이 간단하다. 왜냐면, 삭제된 레코드에 의해서 만들어진 빈 공간에 새로운 레코드를 삽입하면 되기 때문이다.
2. Variable-Length Records
대부분 Variable-Length Records를 필요로 하는 이유는 String과 같은 길이가 변할 수 있는 필드가 존재하기 때문이다.
또한 array와 multiset과 같은 반복 필드를 포함하는 레코드 유형, 그리고 파일 내에 여러 개의 레코드 유형이 존재하는 경우가 있다.
가변 길이 레코드를 구현하기 위한 다양한 기술들이 존재한다. 이때, 각각의 기술들은 2가지 문제점을 반드시 해결해야 한다.
- 각 속성이 가변 길이인 경우에도 개별 속성을 쉽게 추출할 수 있는 방식으로 어떻게 단일 레코드를 표현할 것인가.
- 어떻게 블록 내에 가변 길이 레코드를 저장하고, 블록 내의 레코드를 쉽게 추출할 수 있는 방법은 무엇인가
가변 길이 속성을 가진 레코드는 대표적으로 2개의 부분을 갖고 있다.
1) 고정된 길이 정보를 가진 첫 부분 : 이 부분의 구조는 똑같은 relation의 모든 레코드랑 동일
⇒ 값을 저장할 때 필요로 하는 만큼 bytes 값들을 할당한다. (ex. numeric values, dates)
2) 가변 길이 속성
⇒ 레코드의 앞 부분에서 (offset, length) 쌍으로 표현된다.offset은 레코드에서 데이터가 시작하는 위치를 의미하고 length는 말 그대로 길이를 의미한다.
가변 길이 속성의 값이 연속적으로 저장되고 그 이후에 고정 길이 부분이 저장된다.
이렇게 고정된 형태의 쌍으로 저장되기 때문에 레코드의 앞 부분은 각 속성에 대한 정보를 저장하는데 있어 고정된 사이즈로 저장된다.
ex) 아래 그림에서 정보를 저장하기 위해 4Bytes 씩 고정된 걸 볼 수 있다.

위 그림은 ID, name, dept_name이라는 가변 길이 문자열을 저장한 상황이다. 4번째 속성인 salary는 고정된 길이의 숫자 값이다.
offset과 length가 각각 2바이트 크기로 저장되어서 (offset, length) 쌍이 총 4바이트로 크기로 저장된 걸 볼 수 있다.
중간에 null bitmap을 사용했는데 이는 record의 어떤 속성 값이 null인지 나타낸다.
ex) salary가 null
비트맵의 4번째 비트에는 1이 저장된다. 즉, Null bitmap은 0001이 된다.- 12-19바이트에 저장된 salary 값은 무시된다.
레코드의 속성 값이 4개 있기 때문에 null bitmap은 4자리 비트값(0000, 0001...)을 가질 수 있게 되면서 1bytes의 크기를 갖게 된다.
이렇게 중간에 null bitmap이 있는 표현법은 레코드의 필드 개수가 많지만 대부분 null인 몇몇 응용프로그램에 특히 유용하다.
이 밖에도 null bitmap을 레코드의 맨 처음에 저장해서 저장공간을 아끼는 방식도 존재한다.
다음으로, 블록 내에 가변 길이 레코드를 저장하는 문제를 다룬다.
흔히 slotted-page 구조를 블록 내의 레코드를 구성할 때 사용한다. 이에 대한 그림은 아래와 같다. (여기서 블록은 page와 동일한 단어)

각 블록의 시작부분에는 헤더가 존재한다. 이때, 헤더는 다음과 같은 정보를 갖고 있다.
- 헤드에 있는 record entry의 개수
- 블록에 있는 free space의 마지막 지점
- 배열의 entry가 location과 각 레코드의 size를 포함하고 있는 배열 - records : 블록의 끝에서부터 시작해서 연속적으로 할당되어 있음
- free space : 첫 record와 마지막 header array 사이에 연속적으로 존재
만약에 record가 삽입되었다면
record에 대한 space가 free space의끝에서부터 할당된다.레코드의 size와 location을 갖고 있는 entry는 header에 추가된다.
record가 삭제되었다면
- 차지하고 있던 space는 해제된다.
- 레코드의 entry는 삭제된다.
- 삭제된 레코드 앞에 있던 레코드들은 뒤로 움직이면서 삭제되면서 만들어진 free space가 다시 채워지고 채워져 있었던 맨 앞 1칸을 제외한 나머지 모든 free space가 되돌아온다. 헤더에 있는
end-of-free-space 포인터는 갱신된다.
이렇게 Record는 space의 크기에 따라 커지거나 작아진다. 블록의 사이즈가 제한되기 때문에 레코드를 이동시키는 비용은 크지 않다.
이러한 slotted-page 구조는 레코드를 직접 가리키는 포인터가 없다.
다만, 헤더에 존재하는 실질적인 레코드의 위치 정보를 갖고 있는 entry를 반드시 가리켜야 한다. 이 정도 수준의 우회를 통해 레코드가 움직일 때 블록 내부에 있는 space의 파편화(fragmentation)를 막을 수 있다.
3. Storing Large Objects
종종 disk block보다 큰 데이터를 저장하는 경우가 있다.
대부분의 DB는 내부적으로 레코드의 크기를 블록의 크기보다 커지지 않도록 제한한다. 물론 크기가 큰 object를 저장할 수는 있지만 다른 크기가 작은 속성들과는 별도로 저장한다. 그러고 나면 큰 object를 갖고 있는 레코드에 object를 가리키는 포인터가 저장된다.
큰 object는 데이터베이스에 의해서 관리받는 파일 구조를 통해서 저장될 수 있다. 이때, 큰 object를 표현하기 위해서 B+ 트리 파일 구성을 사용한다. 이에 대해서는 Section 14.4.1에서 자세히 다룬다.
하지만, 굉장히 큰 object를 저장하게 되면 성능상의 이슈가 발생한다.
1) 데이터베이스를 통해 큰 object에 접근하는 것의 효율성
2) 백업 데이터베이스(database dumps라고도 함)의 크기
그래서 많은 응용프로그램은 굉장히 큰 object를 DB가 아닌 다른 파일 시스템에 저장한다. 이 경우에 응용 프로그램은 파일의 이름(일반적으로 파일 경로)을 데이터베이스의 레코드의 속성으로 저장할 수 있다. 하지만, 이렇게 되면 데이터베이스에 존재하지 않는 파일의 이름을 가리킬 수 있어서 외래키 제약 조건을 위배할 수 있고 DB의 인증 제어가 파일 시스템에는 적용되지 않는다.
몇몇 데이터베이스는 파일 시스템을 DB와 통합해서 제약 조건을 만족시키고 접근 인증을 강제한다. 파일에 파일 시스템 인터페이스와 DB SQL 인터페이스를 통해 접근이 가능해진다는 뜻이다.
'DB System Concepts 7th' 카테고리의 다른 글
| [DB] 13-4. Data-Dictionary Storage (0) | 2023.08.03 |
|---|---|
| [DB] Chapter 13-3. Organization of Records in Files (0) | 2023.07.20 |
| [DB] Chapter 13-1. Database Storage Architecture (0) | 2023.07.06 |
| [DB] 12-6. Disk-Block Access (1) | 2023.06.17 |
| [DB] Chapter 12-4. Flash Memory (0) | 2023.06.14 |